지난 01화에서는 파이토치에서 앞으로 우리가 사용할 데이터의 기본 단위인 '텐서' 에 대하여 공부해 보았습니다.
텐서에 대한 개념과 조작법에 익숙해지면 앞으로 우리가 배울 모델들을 이해하고 활용하는데 아주 큰 도움이 되니 충분히 숙지하시길 바라겠습니다.
02화에서는 이제 본격적으로 데이터 사이언스 모델을 다루어 보겠습니다! 선형 회기 (Linear Regression) 이론에 대하여 이해해 보고 이론을 적용한 모델도 만들어 보겠습니다.
선형 회기란?
'선형 회기' 라는 단어를 들었을 때 어떤 생각이 드시나요? 저는 '사자성어야 뭐야...' 라는 생각이 가장 먼저 들었었습니다. 일상적으로 익숙하지 않은 한자를 사용하다보니 와닿지 않는데요, 차라리 영문표기인 Linear Regression 이 더 와 닿는다고 생각해서 선형 회기라는 표현보다는 '리니어 리그레션' 이라고 더 많이 칭하게 되는것 같습니다.
Linear 은 '선형' 입니다. 선, 줄 이라는 뜻의 'Line' 을 어원으로 두고있어서 선에 관련 된 무언가 일것같은 느낌이 듭니다.
Regression 은 re (다시) + gress (돌아가다)라는 어원들이 합해져 '다시 돌아가다' 즉 회기한다는 뜻을 가지고 있습니다.
다시 말해 리니어 리그레션은 '선과 관련지어 다시 돌아간다' 라는 뜻입니다.

위에 그림 처럼 다양한 데이터 포인트가 있는데 가만보니 어떠한 데이터들이 어떠한 패턴을 가지고 있는것 같습니다.
그 패턴이 x 값이 커지면 커질수록 y값도 커지는 패턴을 확인 할 수 있으신데요, 이 패턴을 리니어 리그레션 모델을 사용한다면 임의의 x값을 input 했을 때 정확하진 않겠지만 어느정도 타당한 y 값을 예측할 수 있을것이라 기대됩니다. 이것이 리니어 리그레션의 개념입니다.

이제 파이토치를 활용해 공부시간에 따른 점수를 예측하는 모델을 만들어 보도록 하겠습니다.
공부시간 1시간에 2포인트, 2시간에 4포인트, 3시간에 6포인트를 받았다고 가정했을 때 공부를 4시간을 한다면 몇 포인트를 받을 수 있을지 맞추어 보고자 합니다. 이때 시간과 점수 모두 알고있는 데이터를 묶어 '트레이닝 데이터셋' 이라고 표현합니다. 인풋값과 아웃풋 값을 지정해주고 '이 데이터들의 패턴을 찾아줘!' 하고 컴퓨터에게 부탁하는 것입니다.
그리고 점수를 알고자 하는 데이터 세트를 테스트 데이터 셋이라고 합니다. 테스트 데이터셋에는 인풋요소인 시간 만 포함됩니다. 모델을 통해 트레이닝 세트에서 찾은 패턴을 활용해 아웃풋 값을 예측하기 위해서죠.
이제 파이토치에서 직접 데이터셋을 정의해 보겠습니다!

x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[2], [4], [6]])
이렇게 트레이닝 세트를 input/output 즉 입출력 값, x 와 y 로 나누어 텐서형태로 정의해주었습니다.

우리는 트레이닝 데이터들을 분석해서 패턴을 찾아내는 '식' 을 찾는 작업을 할것입니다. 이 '식' 을 '가설' 혹은 'Hypothesis' 라고 부릅니다.
결과값에 따라서 우리는 이 Hypothesis를 수정하기도 합니다. 리니어 리그레션의 가설은 위에 수식에서 보이는
1차 방정식 'y = Wx + b' 입니다. x값과 y값을 알고 있을 때 W (Weight, 가중치)값과 b(bias, 편향) 값을 알아내어 테스트 세트의 x 값을 넣으면 y값을 예측할 수 있도록 하는 식을 찾는 과정인것입니다.
W = torch.zeros(1, requries_grad=True)
b = torch.zeros(1, requries_grad=True)
torch.zeros를 사용해 W (Weight, 가중치)값과 b(bias, 편향) 값을 0으로 초기화 해줍니다.
W 와 b 에 해당하는 값이 각각 1개씩이므로 괄호 안에는 '1' 이 들어가며
requires_grad 란 gradient (기울기) 가 require, 필요하다, 즉 W와 b 값을 학습하여 예측해야 한다라는 것을 명시해 주는것입니다.
그리고
hypothesis = x_train * W + b로 수식을 정의해 줍니다.
이제 문제 (데이터셋)와 모델(리니어 리그레션 가설)의 정의를 해주었으니 학습(트레이닝)을 해보겠습니다.

데이터 사이언스를 공부하시면서 loss, error, cost, objective 등의 용어들을 계속해서 만나게 되실텐데요, 이 용어들은 모두 '오차'를 표기하는 용어들이며 같은 뜻을 다양하게 호칭한다고 생각해주시면 되겠습니다. 특히 loss 와 cost를 가장 자주 사용합니다.
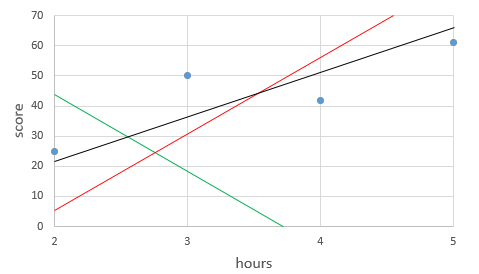
위 그래프에서 보이는 3개의 직선들 중 어느 직선이 네개의 점에 가장 가깝다고 할 수 있을까요?
이것을 판단하기 위해서 우리는 '오차'를 활용하는 것입니다.

가장 정확한 모델을 만들고자 한다면 테스트 데이터에서 얻은 y 값과 트레이닝 데이터의 y 값의 오차가 가장 적은 W와 b를 알아내는것이 중요하겠죠? 리니어 리그레션에서의 오차(cost) 는 예측한 데이터값 (prediction)과 측정값 (Target)의 제곱의 평균으로 구해주는데 이를 Meas Squared Error (MSE) 라고 부릅니다.
이 수식은 파이토치를 사용하면 아래와 같이 간단하게 1줄의 코드로 표현할 수 있습니다.

오차 (cost) 는 수식(hypothesis) 에서 결과값 (y_train) 의 차이의 제곱의 평균을 계산해 주기 위해서 torch.mean 을 활용합니다.

Cost 를 계산한 이후에는 cost 가 가장 낮은 값을 갖을 때의 Weight 와 Bias를 찾기 위한 최적화 (Optimization) 작업인 Gradient Descent 작업에 대해 알아보겠습니다.
위에 Weight 와 Bias를 정의할 때 require_grad = True 라는 명령어를 넣어주어 Weight와 Bias의 기울기 (Gradient) 조절이 필요하다고 명령해주었었습니다. 여기에서의 오차의 기울기인 Gradient의 최소값을 찾아주는 작업을 Gradient Descent라고 부릅니다.
파이토치에서는 편리하게 optim 라이브러리 기능을 써서 Gradient Descent 작업을 실행할 수 있습니다. 리니어 리그레션에서는 SGD (Stochastic Gradient Descent) 방법을 사용해 최적화를 해줍니다.
optimizer = optim.SGD( [W, b], lr = 0.01) 이렇게 optim 라이브러리에서 SGD cost function에 학습할 변수 W와 b 를 리스트로 만들어 넣어주고 Learning rate 인 lr을 설정해 줍니다.
optimizer 의 기울기를 0으로 초기화, cost.backward()를 사용해 기울기를 계산, step을 사용해 기울기를 개선하는 작업을 반복합니다.
이 모든 트레이닝 과정을 전체적인 코드로 확인하며 정리해보겠습니다.

먼저 x 와 y 트레이닝 데이터셋을 정의해주고
변수 W 와 b 를 초기화 하며 requires_grad = True 로 설정해주어 러닝준비를 해줍니다.
최적의 grad를 찾기위해 optimizer를 optim 라이브러리에서 SGD를 통해 설정해주고
nb_epochs 는 몇번 러닝을 해줄지 설정해줍니다. 위 코드에서는 1000번으로 설정해주었습니다.
가설식에 대입하고 각 값의 cost를 계산하고 optimizer.step으로 러닝을 해주고 이 과정을 for 문을 써서 1000번동안 러닝을 실행해 계산해줍니다.

Gradient Descent 에서 일어나는 수학적 개념을 조금 더 알아보겠습니다.
값과 기울기의 오차 평균값을 구하는 cost(W) 는 W에 대한 2차함수임으로 미분을 하여 최소값을 구해주어야 합니다.

반복적인 과정에서 W의 값은 기존 W 에서 러닝 레이트에 gradient 값을 곱한것을 뺀 값으로 산출되는 것입니다.

코드로는 위와같이 표현할 수 있겠습니다.

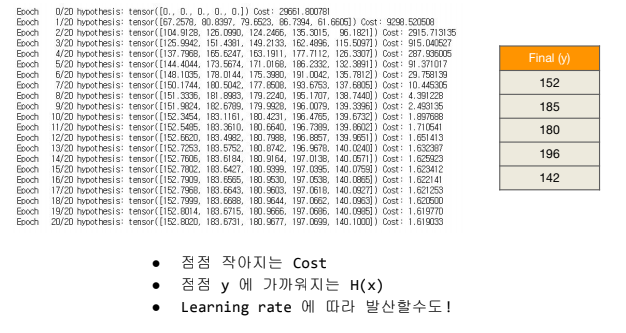
결과적으로 Epoch 가 거듭될 수록 Cost 값이 0으로 수렴하는것을 확인 할 수 있습니다.
그렇다면 여러개의 정보로부터 하나의 값을 리니어 리그레션을 활용해서 어떻게 얻을 수 있을까요?

1, 2, 3번의 퀴즈 점수들과 기말고사 점수의 연관성을 보여주는 데이터셋이 있습니다.
이를 예측할 수 있는 가설인 Hypothesis Function 을 정의해 보겠습니다.

w 와 x 가 1대 1로 대응했던 전 예시와는 다르게 이번에는 3가지의 데이터에 각각 3개의 변수 W가 필요합니다.
위 식을 코드 아래와 같이 표현할수 있겠습니다.

하지만 만약에 데이터가 3개가 아닌 100개, 1000개라고 한다면 수식이 너무 길어지겠지요?

그래서 위와 같이 파이토치의 matmul()을 활용해서 간단하게 표현합니다.
Cost function은 학습시간 예시와 동일하게 MSE를 활용해 줍니다.

hypothesis function과 cost function을 정의했으면 이제 torch.optim을 활용해 Gradient Descent 를 실행합니다.

여러 데이터를 가지고 하나의 값을 예측하는 리니어 리그레션의 코드 전체를 확인해보면 아래와 같이 되겠습니다.


위 코드의 결과값은 아래와 같이 cost 가 0으로 수렴하는 것을 확인하실 수 있습니다.
파이토치에서는 고맙게도 리니어 리그레션 및 많은 모델에서 활용할 수 있는 hypothesis function, cost function 등을 모듈화 해두었습니다. 그래서 우리는 손쉽고 간단하게 파이토치를 활용해서 모듈을 활용하는 법을 익혀두면 더 간단하고 오작동 없는 코드를 짤수 있습니다.


이렇게 nn.module 을 활용할 때의 전체적인 코드를 이전 코드와 비교해보겠습니다.


보시는 것과 같이 모델을 정의할때, Hypothesis를 계산할 때, 그리고 cost function을 계산할 때 이렇게 파이토치에서 제공하는 모듈들을 nn.module 을 통하여 사용하면 앞으로 더 복잡한 수식들을 만나더라도 쉽고 빠르게 딥러닝 모델을 만들어낼수 있습니다.
여기에 더불어 만약 시험점수들 뿐만이 아니라 훨씬 더 복잡한 데이터들을 다루어야 할텐데 그렇게 된다면 코드가 복잡해질 뿐더러 처리해야하는 데이터들이 너무 많아 시간이 많이 걸리고, 또 어떤 문제는 지금 컴퓨팅 파워로 해결하지 못할 수도 있습니다. 하지만 이런 문제를 해결하기 위해서 논리적이고 효율적인 파이토치 기능과 활용법에 대하여 조금 더 알아보도록 하겠습니다.

첫번째로 커다란 데이터셋의 모든 데이터를 전부 러닝에 사용하지 않고 일부분의 데이터만 학습하는 방법인 Minibatch Gradient Descent 라는 방법을 고안해 냈습니다.
전체 데이터를 Minibatch라는 작은 데이터셋으로 나누어 나누어진 batch를 하나하나 학습하는 방법으로 전체 데이터의 cost를 한꺼번에 계산하는 것이 아니라 minibatch의 cost를 계산 한 후 Gradient Descent를 함으로서 컴퓨터에 무리를 덜어주는 굉장히 간단하면서 획기적인 방법론을 사용합니다.

Minibatch Gradient Descent는 컴퓨터에 무리를 주지 않고 조금 더 빠르게 계산을 할 수 있는 장점을 가지고 있지만, 전체 데이터를 활용하지 않아서 비교적으로 오차가 정확하지 않을 수 있다는 단점도 존재합니다. 그래도 물리적으로 불가능한 것을 가능하게 한다는 것에서 매우 훌륭한 방법이라고 생각합니다.

또 다른 대량의 데이터를 활용할 때 쓰는 방법론으로 파이토치에서는 데이터셋과 데이터로더 라는 기능을 제공하고 있습니다. 이 기능을 사용한다면 미니배치 학습, 데이터 셔플 등의 기능을 간단히 처리 할 수 있습니다.
위 코드가 파이토치에서 제공하는 데이터셋 기능이고 이 기능은 새로운 클래스로 데이터셋을 만들어 전체 데이터에서 원하는 부분을 활용 할 수 있게 해줍니다.
__init__()은 데이터셋의 전처리를 수행하고, __len__() 함수는 데이터셋의 총 데이터 수를 반환하며, __getitem__()은 데이터셋에서 특정 1개의 샘플을 torch.tensor() 형태로 가져오는 기능을 합니다.

데이터셋을 정의한 이후에 파이토치의 dataloader 기능을 활용해서 간단히 로드를 할 수 있습니다.