[복숭아 연구주제 12] 비전공자도 떠나는 데이터 사이언스 기행 [파이토치 12 화: Convolution]
오늘은 컴퓨터 비전과 이미지 처리에서 많이 활용되는 기법인 Convolution 에 대해서 알아보도록 하겠습니다.
이 Convolution 이 바로 CNN (Convolutional Neural Network) 의 convolution 입니다!
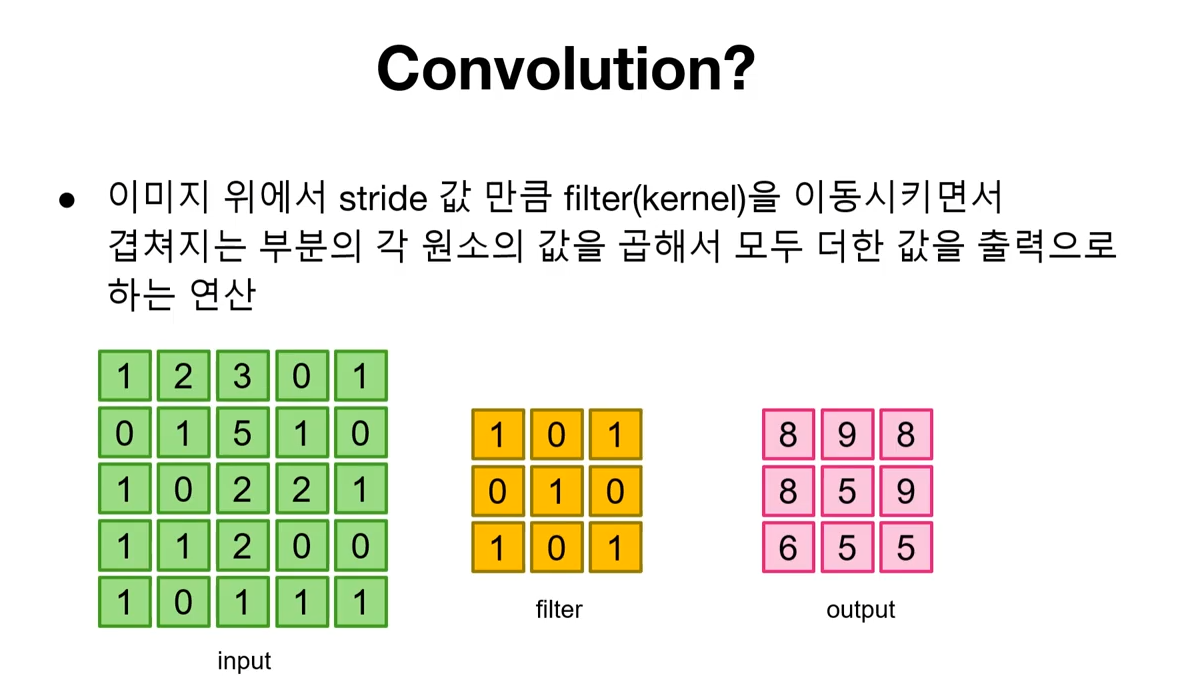
Convolution 이란 위에 나와 있는것 처럼 이미지(input) 위를 필터가 주욱 훑고 지나가면서 연산을 하여 새로운 output 값을 만드는 것을 말합니다. 이런 방식을 활용하면 커다란 이미지 사이즈를 바꿀 수 있고, 이미지의 부분적인 패턴을 파악하여 이미지 내부에 표시 할 수 있습니다.

위와 같이 필터가 표시된 부분에 해당 필터값을 곱하여 전부 더해줌으로서 출력값이 하나가 되고 스트라이드 값 만큼 필터를 움직여 다시 한번 연산을 해줌으로써 새로운 output 값이 나오게 됩니다. output의 shape이 input에 비해 작아진 것을 알 수 있습니다.

Convolution 에서 필터가 움직이는 픽셀값을 stride 라고 합니다.

convolution 연산을 거치면 필터가 거쳐간 만큼 한 값으로 수렴하여 output 값이 input에 비해서 shape 가 작아질 수 밖에 없습니다.
output 사이즈를 같은 크기로 유지해주기 위해서는 padding 이라는 기법을 쓰는데 위에서 보시는 것과 같이 필터 주변에 0으로 된 패드를 둘러쌓아 output의 크기가 작아지는 것을 방지하는 방법입니다.

파이토치에서는 torch.nn.Conv2D 형태로 사용되며 입력값에 (인풋 채널, 아웃풋 채널 커넬 사이즈, stride, 패딩, 딜레이션, 그룹, 바이아스) 순으로 입력을 주는데, 딜레이션이나 그룹은 많이 사용되지 않고 default 값으로 가기에 그냥 무시하셔도 무방합니다.

input 값은 torch.Tensor 로 shape는 배치 사이즈, 채널, 높이, 너비 로 입력됩니다.
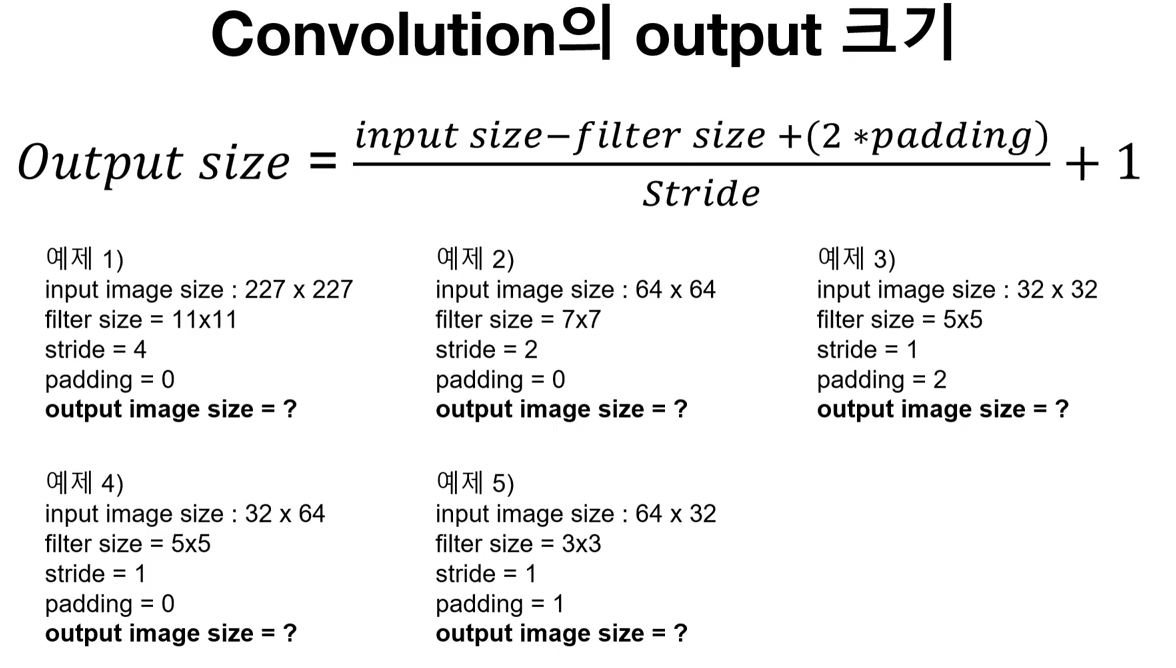
위 예제를 보시면 input 크기, 필터 크기, 패딩과 스트라이드가 output 크기에 미치는 영향을 보여주는 공식입니다. 간단히 수를 대입하면 output 크기를 확인 하실 수 있습니다. 단 스트라이드로 나누어 떨어지지 않을 때 소수점은 버림을 해 주고 +1 을 해줍니다.

그럼 이번에는 이전에 알아본 퍼셉트론과 convolution의 관계에 대해서 알아보겠습니다. 그림과 같이 필터가 있을 때 이 필터들의 요소들은 각각 나누어져 퍼셉트론에 입력이 됩니다.


같은 원리로 필터의 크기와 같은 input 데이터 또한 퍼셉트론에 배치가 되며 해당하는 필터와 input 값을 곱하고 bias를 더해주면 output 값이 나오게 됩니다.

convolution 연산 이외에도 pooling 이라는 기법으로 간단히 이미지 사이즈를 줄인다던가 fully connected 인공신경망 연산을 대체하기도 합니다. Max pooling의 경우는 필터값에 해당하는 input 데이터들 중 가장 큰 값으로 치환하는 방법이고 average pooling은 해당하는 input 데이터들의 평균값으로 치환하는 방법 입니다.

Pooling 은 Conv2d 와 비슷한 형태로 torch.nn.MaxPool2d 로 표현하고 커넬(필터) 사이즈, stride, padding 값, dilation, 리턴 인다이스, 실 모드 순서로 표현하며 참고하시면 좋을 것 같습니다.

그렇다면 위에 보이는 개념을 코드로 직접 구현해 보면서 output의 사이즈가 어떻게 계산이 되는지 확인해 봅니다.

out1 과 out2를 확인해 보면, 계산했던 것과 마찬가지로 결과가 나오는 것을 확신하실 수 있습니다.